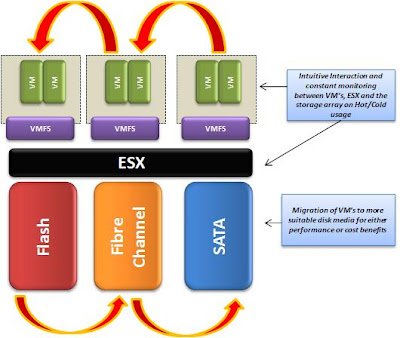
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.
Компания Veeam Software, известная своим продуктом для резервного копирования Veeam Backup and Replication, выпустила финальную версию решения Veeam ONE v6, предназначенного для мониторинга (бывший продукт Veeam Monitor), а также контроля изменений и автоматизированной отчетности (бывший продукт Veeam Reporter) виртуальных инфраструктур VMware vSphere и Microsoft Hyper-V. О новом комплекте поставки решения Veeam ONE мы уже писали тут и тут.
Функции мониторинга:
Функции отчетности:
Теперь два продукта Veeam Reporter и Monitor работают на одном движке с общей базой данных, что делает Veeam ONE законченным решением для управления виртуальной инфраструктурой с точки зрения мониторинга, отчетности, контроля изменений и планирования мощностей. Все в одном.
Новые возможности Veeam ONE v6:
Мониторинг
New monitoring views - новые представления дэшбордов summary, alarm и resource, позволяющие осуществлять быструю навигацию вглубь объектов.
Read-only access to monitoring clients - для клиентов, которым нужны только функции наблюдения за виртуальной средой, можно ограничить права на изменения объектов.
Logical groupings of performance counters - пользователь несколькими кликами может поместить на графики метрики различных категорий для отслеживания возможных зависимостей между ними.
Детализация
Detailed views - для многих объектов можно "проваливаться" вниз с максимальным уровнем детализации.
Child object status display - индикаторы статуса родительских объектов дают представление о том, что происходит с дочерними, и какие у них могут быть проблемы.
Generating reports from widgets - с помощью виджетов в Veeam ONE можно быстро сгенерировать отчет, отражающий заданный период времени.
Тревоги (Alarms)
New alarms - теперь еще большее количество алармов.
Default action - при срабатывании аларма автоматически посылается нотификация по почте всем, кто находится в группе default notification group.
Filtering - фильтры по тревогам могут быть основаны на базе error level, status, object type и времени.
Exclusions - исключения для алармов, которые можно применить к различным объектам: виртуальным дискам, сенсорам оборудования на хостах и т.п.
Email customization - редактирование поля subject и формата нотификаций.
Configurable email notification groups - можно задавать, кто получает нотификации по группам событий.
Отчетность
Overview reports - отчеты по Storage capacity, storage usage, а также обзорные отчеты infrastructure, hypervisor,
clusters и VMs.
Monitoring reports - отчеты по мониторингу: Alarms, uptime ВМ, производительность кластера, хостов и виртуальных машин, включая отчет по потребителям наибольшего количества ресурсов.
(VMware only) Optimization reports - ВМ с перевыделенными или недовыделенными ресурсами, снапшотами, лишними файлами, а также простаивающие ВМ и шаблоны, выключенные ВМ.
(VMware only) Change tracking reports - отслеживание изменений в настройках пользователем или объектом, а также изменения пермиссий.
Integration - дэшборды можно встраивать в письма оповещений, веб-порталы и сторонние приложения.
Access control - для доступа к дэшбордам могут быть заданы разрешения для пользователей.
Автоматическое обновление и бизнес-категоризация
Automatic updates - по запросу Veeam ONE v6 проверяет и загружает обновления репорт-паков, дэшбордов и виджетов.
Business views - представления мониторинга и отчетности могут быть настроены в соответствии с категоризацией, заданной пользователем. Т.е. эти представления можно сделать на основе бизнес или географических критериев.
Standalone hosts - отдельно стоящие хост-серверы также включаются в категоризацию.
Sample categorization - схема бизнес-категоризации, которая показывает пример, как это делать.
Сбор данных в виртуальной среде
Automatically triggered data collection - после установки Veeam ONE сразу же начинается периодический сбор данных с хост-серверов.
Controlled query load - данные о производительности и конфигурации собираются в различных задачах, что позволяет более гибко подходить к распределению нагрузки этими задачами на хост-серверы.
Granular performance history - в Veeam ONE v6 сохраняется гранулярная история производительности за длительный промежуток времени, включающая в себя данные мониторинга и отчетности.
Поддержка VMware vSphere 5
Datastore maximum queue depth - Veeam ONE v6 включает эту новую метрику vSphere 5.
Storage clusters - мониторинг и оповещения по кластерам хранилищ vSphere 5.
Поддержка Microsoft Hyper-V
Alarms - Veeam ONE имеет 90 алармов для хостов и других объектов Hyper-V.
Full monitoring support for Failover Clusters - для кластеров Hyper-V поддерживаются все функции мониторинга, включая алармы, отчеты, чарты и статьи базы знаний для томов CSV.
Direct collection of performance data - данные о производительности собираются напрямую с хост-серверов, включая хосты без SC VMM, что позволяет контролировать больше, чем сам SC VMM.
Решение Veeam ONE v6 для Microsoft Hyper-V и VMware vSphere можно скачать по одной ссылке тут.
Rob de Veij, выпускающий бесплатную утилиту для настройки и аудита виртуальной инфраструктуры VMware vSphere (о ней мы не раз писали), выпусил обновление RVTools 3.3. Кстати, со времен выпуска версии 3.0, RVTools научилась поддерживать ESXi 5.0 и vCenter 5.0.
Новые возможности RVTools 3.3:
Таймаут GetWebResponse увеличен с 5 минут до 10
Новая вкладка с информацией о HBA-адаптерах (на картинке выше)
Приведена в порядок вкладка vDatastore
Функция отсылки уведомлений по почте RVToolsSendMail поддерживает несколько получателей через запятую
Информация о папке VMs and Templates показывается на вкладке vInfo
Несколько исправлений багов
Скачать полезную и бесплатную RVTools 3.3 можно по этой ссылке. Что можно увидеть на вкладках описано здесь.
Недавно мы писали о такой интересной вещи как Managed Object Browser (MOB), которая доступна через веб-сервер, работющий на сервере VMware vCenter (а также напрямую через веб-доступ к ESXi). А что вообще есть еще интересного на этом веб-сервере? Давайте посмотрим:
1. Если вы еще не пользовались веб-клиентом VMware vSphere Web Client в vSphere 5.0, самое время сделать это, зайдя по ссылке:
https://<имя vcenter>
Этот клиент умеет очень многое из того, что делает обычный "толстый" клиент:
2. Там же, на стартовом экране веб-сервера vCenter, вы можете нажать "Browse Datastores in the vSphere Inventory" и просмотреть хранилища, прикрепленные к хостам ESXi, прицепленным к vCenter:
3. Следующая интересная вещь - vCenter operational dashboard, компонент, который позволяет просматривать статистики по различным событиям, произошедшим в виртуальной инфраструктуре vSphere. Он доступен по ссылке:
http://<имя vCenter>/vod/index.html
Смотрите как интересно (кликабельно) - там много разых страничек:
4. Ну и на закуску - просмотр конфигурации и лог-файлов хоста ESXi через его веб-сервер (предварительно должен быть включен доступ по SSH). Зайдите по ссылке:
https://<имя ESXi>/host
Здесь можно ходить по папкам /etc, /etc/vmware и /var/log, исследуя логи хоста и его конфигурацию:
Таги: VMware, vCenter, Web Access, Web Client, vSphere, ESXi, Blogs
О снапшотах виртуальных машин VMware vSphere мы уже много писали (например, можно пискать по тэгу "Snapshot"). Постараемся в этой заметке просуммировать информацию о том, что из себя представляют файлы снапшотов виртуальных машин vSphere 5 и как они обрабатываются.
Для того, чтобы снять снапшот виртуальной машины (virtual machine snapshot), можно кликнуть на ней правой кнопкой в vSphere Client и выбрать соответствующий пункт "Take Snapshot" из контекстного меню:
Далее появится окно снятия снапшота ВМ:
Обратите внимание на опцию "Snapshot the virtual machine's memory". Если эту галку убрать, то снапшот не будет содержать состояние памяти виртуальной машины, т.е. при откате к нему ВМ будет в выключенном состоянии. Плюс такого снапшота - он создается намного быстрее, поскольку не надо сохранять память машины в отдельный файл.
Вторая опция - это возможность "заморозки" файловой системы виртуальной машины на время создания снапшота. Она доступна только при условии установленных в гостевой ОС VMware Tools, в составе которых идет Sync Driver. Эта функциональность нужна для создания консистентного состояния виртуальной машины для снапшота на уровне файловой системы, что особенно необходимо при создании резервных копий (используют все системы резервного копирования для виртуализации, например, Veeam Backup and Replication). Данная возможность (quiesce) поддерживается не всегда - об условиях ее применения можно прочитать тут.
После создания снапшота заглянем в Datastore Browser на хосте VMware ESXi через vSphere Client:
Выделенные зеленым объекты - это абстрации двух снапшотов виртуальных машин. Чтобы понять, что собой представляют эти абстрации, откроем каталог с виртуальной машины в консоли (Putty по SSH):
Здесь мы уже видим, что снапшот на самом деле - это набор из четырех файлов:
<имя ВМ>-[шесть цифр]-delta.vmdk - файл данных диска отличий от базового диска
<имя ВМ>-[шесть цифр].vmdk - заголовочный файл
<имя ВМ>.vmsd - текстовый файл с параметрами снапшота (связи в дереве, SCSI-нода, время создания и т.п.)
<имя ВМ>.vmsn - файл с сохраненной памятью виртуальной машины
Самый главный файл - это, конечно, <имя ВМ>-[шесть цифр]-delta.vmdk. Он содержит блоки данных хранимые в формате так называемых redo-логов (он же дочерний диск - child disk). Он же sparse-диск, то есть диск, который использует технологию Copy-On-Write (COW) при работе с данными. Идея технологии copy-on-write — при копировании областей данных создавать реальную копию только когда ОС обращается к этим данным с целью записи. Таким образом, этот виртуальный диск содержит только измененные от родительского диска области данных (delta).
По умолчанию размер COW-операции составляет 64 КБ, что эквивалентно 128 секторам (подробнее). Но сам снапшот растет блоками данных по 16 МБ. То есть запись 64 КБ данных исходного диска может породить прирост 16 МБ данных в диске снапшота.
Следующий интересный тип файла - <имя ВМ>.vmsd. Это обычный текстовый файл, который можно открыть в редакторе и увидеть все отношения между родительским и дочерними дисками, а также другую интересную информацию:
Ну и последнее - это память виртуальной машины, хранящаяся в файле <имя ВМ>.vmsn. Его, понятное дело, может не быть, если вы создавали снапшот выключенной ВМ или убрали галку, о которой написано в самом начале.
По умолчанию снапшоты складываются в папку на VMFS-томе, где лежит виртуальная машина. Но это размещение можно сменить, поменяв рабочую папку (Working Directory) в настройках виртуальной машины через vSphere Client или в vmx-файле, для чего нужно добавить или поменять строчку:
workingDir="/vmfs/volumes/SnapVolume/Snapshots/"
Кстати, эта же папка задает и размещение файла подкачки ВМ (*.vswp). Если вы его хотите оставить на прежнем месте, нужно добавить строчку:
sched.swap.dir = "/vmfs/volumes/VM-Volume1/MyVM/"
Ну и напоследок, какие операции поддерживаются для виртуальных машин со снапшотами:
Операция
Требования и комментарии
Storage vMotion
Для хостов ESX/ESXi 4.1 или более ранних - не поддерживатся. Для ESXi 5.0 или более поздних - поддерживается.
vMotion
Поддерживается. Файлы снапшотов должны быть доступны на целевом хосте. Необходима версия hardware version 4 или более поздняя (ESX/ESXi 3.5 и выше).
Cold migration
Поддерживается для хостов ESX/ESXi 3.5 или более поздних.
Fault Tolerance
Не поддерживается. Для создания снапшота нужно отключить FT.
Hot clone
Поддерживается, но снапшотов не должно быть больше 31 штуки.
Cold clone
Поддерживается. Однако целевая ВМ будет без снапшотов.
Более подробную информацию о снапшотах можно найти в KB 1015180.
Ну и небольшая подборка ссылок по траблшутингу снапшотов в VMware vSphere:
Alan Renouf, автор множества полезных скриптов PowerCLI для администрирования инфраструктуры VMware vSphere, выпустил очередное обновление своей бесплатной утилиты vCheck 6.
vCheck 6 - это PowerCLI-скрипт, который готовит отчетность по объектам окружения VMware vSphere и отсылает результат на почту администратора, из которого можно узнать о текущем состоянии виртуальной инфраструктуры и определить потенциальные проблемы.
Пример получаемого отчета можно посмотреть тут (кликабельно):
Вот полный список того, что может выдавать скрипт vCheck 6:
General Details
Number of Hosts
Number of VMs
Number of Templates
Number of Clusters
Number of Datastores
Number of Active VMs
Number of Inactive VMs
Number of DRS Migrations for the last days
Snapshots over x Days old
Datastores with less than x% free space
VMs created over the last x days
VMs removed over the last x days
VMs with No Tools
VMs with CD-Roms connected
VMs with Floppy Drives Connected
VMs with CPU ready over x%
VMs with over x amount of vCPUs
List of DRS Migrations
Hosts in Maintenance Mode
Hosts in disconnected state
NTP Server check for a given NTP Name
NTP Service check
vmkernel warning messages ov the last x days
VC Error Events over the last x days
VC Windows Event Log Errors for the last x days with VMware in the details
VC VMware Service details
VMs stored on datastores attached to only one host
VM active alerts
Cluster Active Alerts
If HA Cluster is set to use host datastore for swapfile, check the host has a swapfile location set
Host active Alerts
Dead SCSI Luns
VMs with over x amount of vCPUs
vSphere check: Slot Sizes
vSphere check: Outdated VM Hardware (Less than V7)
VMs in Inconsistent folders (the name of the folder is not the same as the name)
VMs with high CPU usage
Guest disk size check
Host over committing memory check
VM Swap and Ballooning
ESXi hosts without Lockdown enabled
ESXi hosts with unsupported mode enabled
General Capacity information based on CPU/MEM usage of the VMs
vSwitch free ports
Disk over commit check
Host configuration issues
VCB Garbage (left snapshots)
HA VM restarts and resets
Inaccessible VMs
Плюс ко всему, скрипт имеет расширяемую структуру, то есть к нему можно добавлять свои модули для различных аспектов отчетности по конкретным приложениям. Список уже написанных Аланом плагинов можно найти на этой странице.
На сайте onevirt.com появилась интересная и многим полезная бесплатная утилита oneVirt Viewer, позволяющая собрать информацию о хост-серверах ESX/ESXi, виртуальных машинах и хранилищах с нескольких серверов vCenter и использовать ее в целях учета объектов, в том числе используемых лицензий на VMware vSphere.
Обратите внимание на полезный блок Total/Used/Available:
Удобно то, что oneVirt Viewer - утилита кроссплатформенная, работающая на Windows, MacOSX и Linux.
Основные возможности продукта:
Поддержка хостов VMware vSphere 4 и 5 (ESX и ESXi) и их серверов vCenter Server
Возможность экспорта в csv всех таблиц на вкладках
Фильтры для разделов
Информация раздела Licenses: vCenter, vSphere Edition, License Key, Qty, Used, Available, Licensed By
Раздел Hosts: Name, Id, Build, Product, Version, vCenter, IP Address, Subnet Mask, Mac Address, MTU Setting, Maintenance Mode, Power State, CPU Mhz, Processor Qty, Core Qty, CPU Model, Memory, NIC Qty, HBA Qty, Hardware Model, Hardware Vendor.
Раздел VMs (на картинке): Name, vCPU Qty, vRAM(MB), vDisk Qty, vNIC Qty, IP Address, CPU Reservation, Memory Reservation, FT Status, VM Path, Power State, vCenter, Host, Guest OS, vHardware Version, VM Tools Status.
Раздел Templates: Name, vCPU Qty, vRAM(MB), vDisk Qty, vNIC Qty, IP Address, VM Path, Power State, vCenter, Host, Guest OS, vHardware Version, VM Tools Status.
Раздел Snapshots: Name,Created, Id, Quiesced, VM Guest и vCenter
Раздел Datastores: Name, Capacity(GB),Freespace(GB), Type, Maintenance Mode, Shared, vCenter
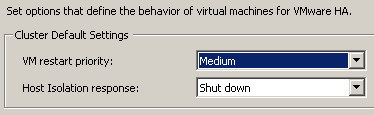
В данной статье объединены все общедоступные на сегодняшний день расширенные настройки кластера VMware HA (с учетом нововведений механизма) для обеспечения высокой доступности сервисов в виртуальных машинах VMware vSphere 5.0 и более ранних версий. Отказоустойчивость достигается двумя способами: средствами VMware HA на уровне хостов ESXi (на случай отказов оборудования или гипервизора) и средствами VMware VM Monitoring (зависание гостевой операционной системы).
На каждом хосте службой VMware HA устанавливается агент Fault Domain Manager (FDM), который пришел на смену агентам Legato AAM (Automated Availability Manager). В процессе настройки кластера HA один из агентов выбирается как Master, все остальные выполняют роль Slaves (мастер координирует операции по восстановлению, а в случае его отказа выбирается новый мастер). Теперь больше нет primary/secondary узлов. Одно из существенных изменений VMware HA - это Datastore Heartbeating, механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами.
Задать Advanced Options для VMware HA (иногда их называют Advanced Settings) можно, нажав правой кнопкой на кластер в vSphere Client и далее выбрав пункт "Edit Settings", где уже нужно вводить их как указано на картинке:
Список Advanced Options для VMware HA, действующих только в vSphere 5.0:
das.ignoreinsufficienthbdatastore - определяет, будет ли игнорировано сообщение о количестве имеющихся Heartbeat-хранилищ, которое меньше сконфигурированного в настройке das.heartbeatdsperhost (по умолчанию - это 2 хранилища). То есть если Heartbeat-хранилище присутствует только одно - будет выведено следующее сообщение:
Выставление значения этого параметра в true уберет это предупреждение из vSphere Client.
das.heartbeatdsperhost - определяет количество Heartbeat-хранилищ, которое можно регулировать данной настройкой (допустимые значения - от 2 до 5). По умолчанию, данное значение равно 2.
das.config.log.maxFileNum - определяет количество лог-файлов, в пределах которого будет происходить их ротация.
das.config.log.maxFileSize - максимальный размер лог-файла, задаваемый в байтах.
das.config.log.directory - путь для хранения лог-файлов VMware HA. При задании настроек логов следует руководствоваться следующей таблицей (подробнее читайте тут на последних страницах):
das.config.fdm.deadIcmpPingInterval - интервал между пингами по протоколу ICMP для определения доступности Slave-хоста ESXi в сети со стороны Master, в случае, если нет коммуникации с FDM-агентом Slave-хоста (используется, чтобы определить - сломался агент FDM или хост вышел из строя). По умолчанию задано значение 10 (секунд).
das.config.fdm.icmpPingTimeout - таймаут, который хост (мастер) ожидает перед получением ответа на пинг, при неполучении которого он считает один из хостов недоступным из сети (то есть время, которое он дает для ответа на пинг, после чего начинаются операции по восстановлению ВМ). По умолчанию задано значение 5 (секунд).
das.config.fdm.hostTimeout - таймаут, который мастер ожидает после события неполученного хартбита от FDM-агента хоста после чего он определяет является ли хост отказавшим (dead), изолированным (isolated) или в другом сегменте разделенной сети (partitioned). По умолчанию задано значение 10 (секунд). Сами же хартбиты между мастером и slave-хостами посылаются каждую секунду.
das.config.fdm.stateLogInterval - частота записи состояния кластера в лог-файл. По умолчанию выставлено в 600 (секунд).
das.config.fdm.ft.cleanupTimeout - когда сервер vCenter инициирует запуск Secondary-машины, защищенной с помощью Fault Tolerance, он информирует мастера HA о том, что он начал этот процесс. Далее мастер ждет время, выставленное в этой настройке, и определяет запустилась ли эта виртуальная машина. Если не запустилась - то он самостоятельно инициирует ее повторный запуск. Такая ситуация может произойти, когда во время настройки FT вдруг вышел из строя сервер vCenter. По умолчанию задано значение 900 (секунд).
das.config.fdm.storageVmotionCleanupTimeout - когда механизм Storage vMotion перемещает виртуальную машину с/на хосты ESX 4.1 или более ранней версии, может возникнуть конфликт, когда HA считает, что это не хранилище ВМ переместилось, а сама ВМ отказала. Поэтому данная настройка определяет, сколько времени мастеру нужно подождать, чтобы завершилась операция Storage vMotion, перед принятием решения о перезапуске ВМ. См. также нашу заметку тут. По умолчанию задано значение 900 (секунд).
das.config.fdm.policy.unknownStateMonitorPeriod - определяет сколько агент мастера ждет отклика от виртуальной машины, перед тем как посчитать ее отказавшей и инициировать процедуру ее перезапуска.
das.config.fdm.event.maxMasterEvents - определяет количество событий, которые хранит мастер операций HA.
das.config.fdm.event.maxSlaveEvents - определяет количество событий, которые хранят Slave-хосты HA.
Список Advanced Options для VMware HA в vSphere 5.0 и более ранних версиях:
das.defaultfailoverhost- сервер VMware ESXi (задается короткое имя), который будет использоваться в первую очередь для запуска виртуальных машин в случае сбоя других ESXi. Если его емкости недостаточно для запуска всех машин – VMware HA будет использовать другие хосты.
das.isolationaddress[n] - IP-адрес, который используется для определения события изоляции хостов. По умолчанию, это шлюз (Default Gateway) сервисной консоли. Этот хост должен быть постоянно доступен. Если указано значение n, например, das.isolationaddress2, то адрес также используется на проверку события изоляции. Можно указать до десяти таких адресов (диапазон n от 1 до 10).
das.failuredetectioninterval - значение в миллисекундах, которое отражает время, через которое хосты VMware ESX Server обмениваются хартбитами. По умолчанию равно 1000 (1 секунда).
das.usedefaultisolationaddress - значение-флаг (true или false, по умолчанию - true), которое говорит о том, использовать ли Default Gateway как isolation address (хост, по которому определяется событие изоляции). Параметр необходимо выставить в значение false, если вы планируете использовать несколько isolation-адресов от das.isolationaddress1 до das.isolationaddress10, чтобы исключить шлюз из хостов, по которым определяется событие изоляции.
das.powerOffonIsolation - значение флаг (true или false), используемое для перекрытия настройки isolation response. Если установлено как true, то действие «Power Off» - активно, если как false - активно действие «Leave powered On». Неизвестно, работает ли в vSphere 5.0, но в более ранних версиях работало.
das.vmMemoryMinMB - значение в мегабайтах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше памяти на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МБ.
das.vmCpuMinMHz - значение в мегагерцах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше ресурсов процессора на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МГц (vSphere 4.1) и 32 МГц (vSphere 5).
das.conservativeCpuSlot - значение-флаг (true или false), определяющее как VMware HA будет рассчитывать размер слота, влияющего на admission control. По умолчанию установлен параметр false, позволяющий менее жестко подходить к расчетам. Если установлено в значение true – механизм будет работать как в VirtualCenter 2.5.0 и VirtualCenter 2.5.0 Update 1. Неизвестно, осталась ли эта настройка актуальной для vSphere 5.0.
das.allowVmotionNetworks - значение-флаг, позволяющее или не позволяющее использовать физический адаптер, по которому идет трафик VMotion (VMkernel + VMotion Enabled), для прохождения хартбитов.Используется только для VMware ESXi. По умолчанию этот параметр равен false, и сети VMotion для хартбитов не используются. Если установлен в значение true – VMware HA использует группу портов VMkernel с включенной опцией VMotion.
das.allowNetwork[n] – имя интерфейса сервисной консоли (например, ServiceConsole2), который будет использоваться для обмена хартбитами. n – номер, который отражает в каком порядке это будет происходить. Важно! - не ошибитесь, НЕ пишите das.allowNetworkS.
das.isolationShutdownTimeout - значение в секундах, которое используется как таймаут перед срабатыванием насильственного выключения виртуальной машины (power off), если не сработало мягкое выключение из гостевой ОС (shutdown). В случае выставления isolation response как shutdown, VMware HA пытается выключить ее таким образом в течение 300 секунд (значение по умолчанию). Обратите внимание, что значение в секундах, а не в миллисекундах.
das.ignoreRedundantNetWarning - значение-флаг (true или false, по умолчанию false), который при установке в значение false отключает нотификацию об отсутствии избыточности в сети управления («Host xxx currently has no management network redundancy»). По умолчанию установлено в значение false.
Настройки VM Monitoring для VMware HA платформы vSphere 5.0 и более ранних версий:
das.vmFailoverEnabled - значение-флаг (true или false). Если установлен в значение true – механизм VMFM включен, если false – выключен. По умолчанию установлено значение false.
das.FailureInterval - значение в секундах, после которого виртуальная машина считается зависшей и перезагружается, если в течение этого времени не получено хартбитов. По умолчанию установлено значение 30.
das.minUptime - значение в секундах, отражающее время, которое дается на загрузку виртуальной машины и инициализацию VMware Tools для обмена хартбитами. По умолчанию установлено значение 120.
das.maxFailures - максимальное число автоматических перезагрузок из-за неполучения хартбитов, допустимое за время, указанное в параметре das.maxFailureWindow. Если значение das.maxFailureWindow равно «-1», то das.maxFailures означает абсолютное число отказов или зависаний ОС, после которого автоматические перезагрузки виртуальной машины прекращаются, и отключается VMFM. По умолчанию равно 3.
das.maxFailureWindow - значение, отражающее время в секундах, в течение которого рассматривается значение параметра das.maxFailures. По умолчанию равно «-1». Например, установив значение 86400, мы получим, что за сутки (86400 секунд) может произойти 3 перезапуска виртуальной машины по инициативе VMFM. Если перезагрузок будет больше, VMFM отключится. Значение параметра das.maxFailureWindow может быть также равно «-1». В этом случае время рассмотрения числа отказов для отключения VMFM – не ограничено.
Настройки, которые больше не действуют в vSphere 5.0:
das.failuredetectiontime
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Раньше была настройка das.failuredetectiontime - это значение в миллисекундах, которое отражает время, через которое VMware HA признает хост изолированным, если он не получает хартбитов (heartbeats) от других хостов и isolation address недоступен. После этого срабатывает действие isolation response, которое выставляется в параметрах кластера в целом, либо для конкретной виртуальной машины. По умолчанию, значение равно 15000 (15 секунд). Рекомендуется увеличить это время до 60000 (60 секунд), если с настройками по умолчанию возникают проблемы в работе VMware HA. Если у вас 2 интерфейса обмена хартбитами - можно оставить 15 секунд.
В VMware vSphere 5, в связи с тем, что алгоритм HA был полностью переписан, настройка das.failuredetectiontime для кластера больше не акутальна.
Теперь все работает следующим образом (см. также новые das-параметры, которые были описаны выше).
Наступление изоляции хост-сервера ESXi, не являющегося Master (т.е. Slave):
Время T0 – обнаружение изоляции хоста (slave).
T0+10 сек – Slave переходит в состояние "election state" (выбирает "сам себя").
T0+25 сек – Slave сам себя назначает мастером.
T0+25 сек – Slave пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+30 сек – Slave объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Наступление изоляции хост-сервера ESXi, являющегося Master:
T0 – обнаружение изоляции хоста (master).
T0 – Master пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+5 сек – Master объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Как мы видим, алгоритм для мастера несколько другой, чтобы при его изоляции остальные хосты ESXi смогли быстрее начать выборы и выбрать нового мастера. После падения мастера, новый выбранный мастер управляет операциями по восстановлению ВМ изолированного хоста. Если упал Slave - то, понятное дело, восстановлением его ВМ управляет старый мастер. И да, помним, что машины будут восстанавливаться, только если в Isolation Responce стоит Shutdown или Power Off, чтобы хост мог их погасить.
das.bypassNetCompatCheck
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Это значение-флаг (true или false, по умолчанию false), который будучи установлен в значение true позволяет обойти дополнительную проверку на совместимость с HA. В VirtualCenter Update 2 была введена проверка на совместимость подсетей, по которым ходят хартбиты. Возникала ошибка: «HA agent on in cluster in has an error Incompatible HA Network: Consider using the Advanced Cluster Settings das.allowNetwork to control network usage». Теперь, если сети считаются несовместимыми с точки зрения HA, однако маршрутизируемыми – новая опция поможет осуществить корректную настройку кластера.
Таги: VMware, HA, FDM, VMachines, ESXi, Обучение, vSphere
Как вы знаете, в VMware vSphere 5 версия файловой системы VMFS была продвинута до 5. Это дает множество преимуществ по сравнению с VMFS 3, в частности, возможность создания хранилищ виртуальных машин (Datastore) размером до 64 ТБ без необходимости создания экстентов.
Это стало возможным благодаря использованию GPT-разделов (GUID Partition Table) вместо MBR-разделов (Master Boot Record). При этом, существует ошибочное мнение, что для томов VMFS 3, обновляемых на VMFS 5, ограничения старой версии в 2 ТБ на файловую систему Datastore остаются. Это не так - VMFS 5.0 при обновлении на нее с третьей версии действительно сохраняет формат MBR, однако после расширения тома более 2 ТБ происходит автоматическая конвертация MBR в GPT-диск.
То есть, происходит это так. У нас есть том VMFS 3, мы нажимаем ссылку "Upgrade to VMFS 5":
После прохождения мастера обновления, видим что тип тома - VMFS 5:
Однако здесь также видно, что том VMFS (теперь уже 5-й версии) остался размеров в 2 ТБ, несмотря на то, что LUN может быть более 2 ТБ. Кроме того, том остался MBR-форматированным, а размеры блоков VMFS 3 для него остались неизменными (см. KB 1003565). Надо отметить, что вновь создаваемые тома VMFS 5 всегда создаются с унифицированным размером блока - 1 МБ.
Чтобы расширить том VMFS, вызываем мастер "Increase Datastore Capacity":
Расширяем том, например до 3 ТБ:
Обратите внимание, что VMFS 5 не дает нам увеличения размера файла (vmdk) по сравнению с предыдущей версией - максимум по прежнему 2 ТБ, просто теперь том может быть размером до 64 ТБ без экстентов.
Запустим fdisk, посмотрим свойства расширенного тома и увидим, что он теперь GPT-том:
Далее операции с таким диском производятся с помощью утилиты partedUtil, но это уже другая история.
Многие пользователи VMware vSphere не пользуются средством автоматизированного обновления хост-серверов VMware Update Manager по тем или иным причинам. Кроме того, пользователи бесплатного VMware ESXi 5 хотели бы обновлять свои хост-серверы, потому как даже эта бесплатная платформа используется в компаниях в производственной среде. Если раньше можно было обновлять хосты ESX/ESXi 4 прямо из vCLI (vihostupdate), то теперь патч нужно загрузить на хранилище (Datastore).
Ниже представлен способ обновления VMware ESXi 5 без VMware Update Manager:
1. Загрузите нужный патч для VMware ESXi 5 с VMware Patch Portal в формате zip-файла.
2. Убедитесь, что на хосте включен доступ по SSH, а также на нем нет запущенных виртуальных машин (или переведите его в Maintenance Mode).
3. Скопируйте патч ESXi 5 в один из Datastore'ов (общий или локальный) с помощью бесплатной утилиты FastSCP. Лучше использовать общее хранилище, чтобы с одного файла патча обновлять несколько хостов.
5. После этого начнется обновления хост-сервера VMware ESXi 5, по окончании которого его нужно будет перезагрузить.
Патч для ESXi можно накатить и через PowerCLI (но загрузить патч на Datastore все равно придется). Для этого можно использовать скрипт от Justin Guidroz.
Возвращаемся к проблеме тонких (thin) дисков VMware ESXi и уменьшения их размера после того, как они разрослись. Суть проблемы: когда вы используете тонкие диски для виртуальных машин - они постоянно растут, даже если вы удаляете в гостевой ОС. Это происходит потому, что ОС Windows (да и Linux) при удалении файлов не заполняет их блоки нулями, а просто помечает их удаленными в метаданных тома.
Многие из вас знают продукт номер 1 для резервного копирования виртуальных машин VMware vSphere - Veeam Backup and Replication. Мы уже много писали как о функциональности Veeam Backup and Replication 5, так и о новых возможностях, которые появляются в Veeam Backup and Replication 6. В среду, 30 ноября, должен состояться релиз новой версии продукта, поэтому постараемся в этой статье собрать все новые функции, улучшения и нововведения Veeam Backup and Replication 6 (обратите также внимание на повышение цен на продукт с 1 декабря).
Приведенная ниже информация основана на документе "Veeam Backup & Replication. What's new in v6", который вы можете почитать в оригинале для понимания всех аспектов новых возможностей этого средства для резервного копирования виртуальных машин.
Новые ключевые возможности и улучшения Veeam Backup and Replication 6:
Enterprise scalability: улучшенная архитектура продукта позволяет производить развертывание в удаленных офисах и филиалах, а также для больших инсталляций. Теперь появилось несколько backup proxy серверов для крупных окружений (data movers), которые могут распределять между собой нагрузку в процессе резервного копирования, а управляет процессом сервер Veeam Enterprise Manager. Виртуальные машины динамически назначаются proxy-серверам с учетом алгоритма балансировки нагрузки, что снижает затраты на администрирование инфраструктуры РК. Также увеличена производительность для резервного копирования, репликации и восстановления по WAN-каналам.
Advanced replication: в некоторых случаях скорость репликации выросла до 10 раз, а также появится Failback (обратное восстановление виртуальной машины после возобновления работы отказавшего хоста с ВМ) с возможностью синхронизации дельты (различия данных с момента отказа основной машины на основном сервере и хранилище - Failover). Кроме того, поддерживается репликация в thin provisined-диски на целевой сервер. Это сильная заявка на победу над VMware SRM 5 (в издании Standard) для небольших компаний, где серверов не много и нужно укладываться в небольшие бюджеты. Появилась также возможность создания реплик базового образа для окружений VMware View.
Multi-hypervisor support: полная поддержка Windows Server с ролью Hyper-V и Microsoft Hyper-V Server, а также возможность управления резервным копированием для гипервизоров разных производителей из одной консоли. Одна и та же инсталляция Veeam Backup позволит делать резервные копии и с VMware vSphere, и с Microsoft Hyper-V. При этом лицензирование также единое - один пул лицензий Veeam вы можете распределить между лицензиями на процессоры для хостов ESXi и Hyper-V. Кроме того, появилась поддержка методики Changed Block Tracking для Hyper-V для ускорения процесса инкрементального резервного копирования (отслеживание изменившихся блоков с момента последнего бэкапа).
1-Click File Restore - с помощью 1-Click File Restore можно зайти в Enterprise Manager, выбрать нужный файл и восстановить туда, откуда он был удален (это можно сделать также из результатов поиска файла по резервным копиям). При этом есть разделение ролей - есть тот, кто может файл восстановить (helpdesk), а есть тот, кто открыть. Данная возможность доступна только в Enterprise Edition.
Полный список новых возможностей:
Архитектура Veeam Backup and Replication 6
ESXi-centric processing engine - теперь архитектура продукта полностью опирается на архитектуру ESXi, но в поддержка гипервизора ESX остается в полной мере.
Backup proxy servers - один сервер Veeam Backup может контролировать несколько прокси-серверов, обеспечивающих передачу данных на целевые хранилища. Прокси-серверы не нуждаются в Microsoft SQL
Server и содержат минимальный набор компонентов.
Backup repositories - новая концепция репозиториев резервного копирования (в традиционном РК известная как медиа-серверы), которые хранят настройки задач резервного копирования и параметры целевых хранилищ. Задачи по РК виртуальных машин с помощью медиа-серверов динамически назначаются proxy-серверам с учетом алогоритма балансировки нагрузки.
Windows smart target - в дополнение к Linux target agent, который помогает при резервном копировании в удаленные хранилища, появился также агент для Windows. Этот агент на целевой машине позволяет производить эффективную компрессию и обновлять синтетические резервные копии.
Enhanced vPower scalability - теперь можно использовать несколько серверов vPower NFS. Теперь можно запускать еще больше ВМ напрямую из резервных копий (например, если у вас много ВМ с большими дисками это очень может помочь). Любой сервер РК Veeam или Windows backup repository может быть таким сервером.
Ядро продукта Veeam Backup and Replication 6
Optimization of source data retrieval - теперь учитываются параметры дисковых хранилищ при обращении к виртуальным машинам. Это позволяет до 4-х раз увеличить производительность для одной операции, в зависимости от настроек дискового массива.
Reduced CPU usage - теперь в два раза меньше нагрузка задач на процессор, что позволяет запустить больше задач РК или репликации на одном сервере Veeam Backup или прокси-сервере.
Traffic throttling - теперь доступны опции по регулированию полосы пропускания, которые производятся на базе пары source/target IP. Эти правила могут быть основаны на времени операций - время дня или день недели.
Multiple TCP/IP connections per job - теперь агенты Data Movers могут инициировать соединение по нескольким IP-адресам, что существенно увеличивает скорость резервного копирования. Особенно это эффективно для репликации по WAN-каналам.
WAN optimizations - протокол передачи данных Veeam Backup был существенно доработан в плане производительности для передачи данных по соединениям с большими задержками в канале.
Exclusion of swap files - блоки, относящиеся к файлам подкачки, теперь исключаются из передачи в резервную копию, что существенно увеличивает производительность.
Enforceable processing window - теперь для каждой задачи можно задавать окно РК или репликации (все задачи, не попадающие в это окно завершаются). Также вне рамок окна не разрешается применение снэпшотов, что не позволяет оказывать влияние на производительность ВМ в рабочие часы.
Parallel backup and replication - теперь задачи, относящиеся к одной и той же ВМ, могут быть выполнены параллельно. Например, вы можете запускать ежедневную задачу Full Backup параллельно с работающей задачей репликации.
Улучшения резервного копирования в Veeam Backup and Replication 6
Backup mapping - при создании новой задачи резервного копирования ВМ, ее можно присоединить к уже имеющейся задаче (например, в ней есть уже файлы этой ВМ). В этом случае Full Backup этой ВМ может не потребоваться.
Enhanced backup file format - новый формат метаданных позволяет осуществлять быстрый импорт резервных копий, а также закладывает основу для поддержки новой функциональности в следующих релизах продукта.
Backup file data alignment - данные ВМ, сохраненные в бэкап-файле, могут быть размещены в пределах блоков по 4 КБ. Это увеличивает производительность дедупликации как самого Veeam Backup, так и сторонних технологий дедупликации (например, средствами дискового массива).
Improved compatibility with deduplicating storage - теперь механизм РК оказывает меньшее влияние на предыдущие файлы резервной копии, что улучшает производительность массивов, которые осуществляют пост-процессинг хранимых данных.
Репликация Veeam Backup and Replication 6
New replication architecture - теперь репликация использует двухагентную архитектуру, которая позволяет собирать данные хранилищ ВМ на исходном DR-сайте одним прокси-сервером РК и посылать их напрямую к прокси-серверу резервной площадки (и наоборот), минуя главный сервер Veeam Backup. Поэтому теперь не разницы, где размещать последний.
Replica state protection - теперь инкрементальные задачи репликации больше не обновляют последнюю точку восстановления ВМ. Это позволяет при прерывании задачи не перестраивать последнюю точку восстановления до того, как следующая задача откатит ее к последнему согласованному состоянию, как в прошлых версиях. В версии 6 последняя точка восстановления всегда согласована и ВМ может быть запущена в любой момент.
Traffic compression - за счет новой архитектуры репликации теперь не важно где находится основной сервер РК Veeam, а трафик сжимается намного более эффективно. Кроме того, появились настройки уровня компрессии для передаваемого трафика, что позволяет уменьшить требования к полосе пропускания до 5 раз.
Hot Add replication - теперь прокси-сервер на целевой площадке представляет диски реплики, используя технологию Hot Add. Это уменьшает поток трафика до 4 раз.
1-click automated failback - позволяет произвести обратное восстановление (Failback) виртуальной машины после возобновления работы отказавшего хоста с ВМ с возможностью синхронизации только дельты с момента последнего отказа (Failover), т.е. различия данных с момента отказа основной машины на основном сервере и хранилище) . Перед завершением этого процесса можно проверить ВМ на работоспособность на основной площадке.
1-click permanent failover - возможность в один клик провести все необходимые процедуры по завершению процесса превращения резервной машины в основную, когда в случае отказа основной ВМ она переместилась на резервный сайт.
Active rollbacks - репликация теперь хранит точки восстановления как обычные снапшоты ВМ. Это позволяет откатиться в любую точку на резервной площадке, даже без участия Veeam Backup.
Improved replica seeding - улучшения механизма организации репликации. Теперь репликация использует обычные бэкап-файлы, это позволяет уменьшить размер передаваемых данных, поддерживаются ВМ с тонкими (thin) дисками и многое другое.
Replica mapping - теперь реплицируемую виртуальную машину можно привязать к уже существующей ВМ на резервной площадке (например, ранее для нее использовалась репликация или на резервную площадку ее восстановили из резервной копии). Это позволяет не передавать весь объем данных для создания реплицируемой пары.
Re-IP - теперь можно задать правила автоматического назначения IP-адреса для восстанавливаемой ВМ. Это очень полезно, когда требуется восстановить ВМ на резервную площадку, где действует другая схема IP-адресации, в случае сбоя основной.
Cluster target - задачи репликации теперь поддерживают указание определенного хоста или кластера как целевого для репликации. Это позволяет убедиться в том, что при восстановлении ВМ она окажется доступной (например, на резервной площадке).
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches технологией репликации, что позволяет передавать состояние реплики без дополнительных ручных операций (например, в окружениях с VMware vCloud Director).
Automatic job update - операции failover и failback автоматически обновляют задачу репликации путем исключения из нее ВМ и повторного добавления.
Multi-select operations - в консоли теперь можно выбрать несколько ВМ для операций с репликацией. Например, при массовом выходе из строя хостов можно провести операции failover сразу с несколькими ВМ (аналогично и для failback).
Enhanced job configuration - теперь мастер создания реплицируемой пары поддерживает возможность настройки репликации на уровне vmdk-дисков, а также предоставляет возможность настроить целевые объекты: resource pool, VM folder и virtual network, где будет размещаться реплика и восстанавливаться ВМ.
Миграция виртуальных машин в Veeam Backup and Replication 6
Quick Migration - эта технология позволяет организовать миграцию виртуальной машины между хостами и/или хранилищами путем передачи данных ВМ в фоновом режиме (пока она запущена) и потом на время простоя (переключения) передается только дельта файлов vmdk. Переключение осуществляется с помощью технологии SmartSwitch или просто повторной загрузкой ВМ. По сути, эта функция - аналог vMotion и Storage vMotion, но с небольшим простоем ВМ.
SmartSwitch - эта технология позволяет передать текущее состояние ВМ от исходного хоста и хранилища к источнику на время переключения виртуальной машины между ними (с простоем). При этом процессоры исходного и целевого хостов должны быть совместимы по инструкциями.
Migration jobs - новый тип задач "миграция ВМ". С учетом имеющейся у вас лицензии на VMware vSphere, мастер миграции выполняет одну из следующих задач: VMware vMotion, VMware Storage vMotion, Veeam Quick Migration
with SmartSwitch или Veeam Quick Migration with cold switch. Это позволяет быстро перевести ВМ с хостов, для которых требуется срочное обслуживание или останов (например, электричество выключили, а они на UPS'ах) или перенести ВМ в другой датацентр с минимальным влиянием на доступность сервисов в ВМ.
Instant VM Recovery integration - задачи миграции ВМ теперь оптимизированы для работы с функцией Instant VM Recovery. Если задача миграции обнаруживает, что ВМ переносится из состояния, когда она была мгновенно восстановлена (т.е. дельта размещается на vPower NFS datastore), то постоянная составляющая этой ВМ берется из бэкап-файла, а различия уже с NFS-хранилища для ускорения процесса миграции и оптимизации производительности.
Копирование файлов в Veeam Backup and Replication 6
Support for copying individual file - поддержка копирования отдельных файлов. Задача по копированию файлов теперь поддерживается так же, как и для каталогов.
Восстановление виртуальных машин в Veeam Backup and Replication 6
1-click VM restore - при восстановлении ВМ в исходное размещение (самый частый случай), это может быть сделано в один клик.
Virtual Disk Restore wizard - новый режим восстановления позволяет восстановить отдельные vmdk-диски в их исходное размещение или присоединить к другой или новой ВМ. При этом мастер Virtual Disk Restore может восстанавливать диски как "thin" (т.е. растущими по мере наполнения данными), а также делает все необходимые настройки в заголовочном vmdk-файле.
Hot Add restores - Veeam Backup первым стал поддерживать технологию Hot Add не только для РК, но и для восстановления vmdk-дисков, что позволяет избежать проблем производительности.
Multi-VM restore - возможность восстановления сразу многих ВМ из графического интерфейса, что очень удобно для случаев массовых отказов хранилищ или хост-серверов.
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches и улучшения в интерфейсе по интеграции с ним (что удобно, например, при использовании совместно с vCloud Director).
Network mapping - при восстановлении виртуальных машин на сервер или площадку с другой конфигурацией виртуальных сетей, можно указать новые параметры сетевого взаимодействия.
moRef preservation - при восстановлении ВМ с заменой существующей копии, ее идентификатор сохраняется, что позволяет не перенастраивать задачи Veeam, а также стороннее ПО, работающее с виртуальными машинами по их идентификатору (почти все так и работают).
Восстановление на уровне файлов в Veeam Backup and Replication 6
Support for GPT and simple dynamic disks - теперь восстановление на уровне файлов поддерживает тома GPT и simple dynamic disks.
Preservation of NTFS permissions - опционально при восстановлении файлов Windows можно сохранить владельца и права на них в NTFS.
Индексирование и поиск файлов в резервных копиях Veeam Backup and Replication 6
Optional Search Server - теперь поиск по файлам гостевой ОС работает без Microsoft Search Server. Однако он рекомендуется для больших окружений с сотнями ВМ для лучшей производительности.
Reduced catalog size - размер каталога файловой системы гостевых ОС существенно уменьшился, что позволяет экономить место на сервере Veeam Backup.
User profile indexing - появилась поддержка индексации профиля пользователя в гостевой ОС.
Статистика и отчетность в Veeam Backup and Replication 6
Enhanced real-time statistics - теперь статистика в реальном времени по задачам РК улучшена в плане дизайна, чаще обновляется и более информативна для пользователя.
Improved job reports - отчеты о задачах РК лучше выглядят, имеют дополнительную информацию, включая количество изменившихся данных, уровень компрессии и коэффициент дедупликации.
Bottleneck monitor - в ответ на наиболее частые вопросы о низкой производительности в различных окружениях, Veeam сделала новый компонент, который позволяет выявить узкие места на различных стадиях РК и репликации. Все это отображается в статистике реального времени.
VM loss warning - история задач РК теперь оповещает пользователя о виртуальных машинах, которые раньше бэкапились, а потом задачи РК перестали существовать (например, случайно или намеренно удалили).
Интерфейс пользователя консоли Veeam Backup and Replication 6
Wizard improvements - все мастера были обновлены для возможности быстрой навигации при создании задач РК. Некоторые мастера стали динамическими - т.е. сфокусированными только на той задаче, которую вы хотите выполнить.
VM ordering - мастера резервного копирования и репликации теперь позволяют задать порядок, в котором ВМ должны обрабатываться.
Multi-user access - доступ нескольких пользователей к консоли теперь включен по умолчанию, позволяя нескольким пользователям получить доступ к консоли по RDP на одном сервере.
Веб-интерфейс Enterprise Manager в Veeam Backup and Replication 6
Job editing - в дополнение к управлению задачами, Enterprise Manager позволяет теперь менять их настройки для защищаемых ВМ, бэкап-репозитории, учетную запись гостевой ОС - все прямо из веб-интерфейса.
Job cloning - существующие задачи теперь могут быть клонированы прямо из веб-интерфейса с сохранением всех настроек.
Helpdesk FLR - появилась новая роль "File Restore Operator" в Enterprise Manager, которой делегированы полномочия по восстановлению отдельных файлов. Ее можно назначить персоналу службы help desk. При этом файлы восстанавливаются в их исходное размещение, а персоналу hepl desk можно ограничить возможности их скачивания, и, соответственно, доступа к ним (есть настройки касательно типов файлов и прочее).
FIPS compliance - веб-интерфейс теперь полностью совмести с стандартом FISP.
Design improvements - веб-интерфейс имеет множество улучшений в плане юзабилити и дизайна.
Улучшения технологии SureBackup в Veeam Backup and Replication 6
Improved DC handling - теперь улучшена работа с контроллерами домена в ситуациях, когда он оказывается изолированным в окружениях с несколькими DC.
Support for unmanaged VMware Tools - задачи SureBackup теперь поддерживают виртуальные машины с пакетами VMware Tools, которые установлены вручную.
Остальные улучшения Veeam Backup and Replication 6
Enhanced PowerShell support - расширены возможности PowerShell API, что позволяет управлять всеми настройками Veeam Backup. Все командлеты PowerShell были упрощены в плане синтаксиса (старый синтаксис также поддерживается). Появились маски в именах объектов, поиск объектов - все аналогично возможностям в консоли.
Log collection wizard - новый мастер, который собирает лог-файлы с защищенных хостов и подготавливает пакет, необходимый при обращении в техподдержку Veeam.
1-click automated upgrade - все компоненты продукта, включая те, что установлены на удаленной площадке (backup
proxy servers и backup repositories), могут быть просто обновлены с использованием мастера Upgrade wizard. При открытии консоли, Veeam Backup & Replication автоматически определяет компоненты решения, которые следует обновить.
Продукт Veeam Backup and Replication 6 должен быть доступен для скачивания с сайта Veeam ориентировочно в среду на странице загрузки продукта.
Несколько скриншотов. Восстановление файла резервной копии из результатов поиска в Enterprise Manager:
Настройки Traffic Throttling:
Мастер восстановления виртуальной машины Microsoftc Hyper-V:
Настройка бэкап-репозиториев:
Настройки Re-IP при восстановлении на резервной площадке:
Часто бывает, что от хоста ESX/ESXi нужно отвязать Datastore и LUN, на котором это виртуальное хранилище находится. При этом важно избежать ситуации All Paths Down (APD) - когда на хосте все еще остались пути к устройству, а самого устройства ему больше не презентовано. В этом случае хост ESX/ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути.
В этом случае из-за APD хоста начнут возникать задержки других задач (поскольку таймауты большие), что может привести к различным негативным эффектам вплоть до отключения хоста от vCenter.
ESX/ESXi 4.1
В версии ESX/ESXi 4.1 демон hostd проверяет том VMFS на доступность прежде чем слать туда команды ввода-вывода (I/Os) Но это не помогает для тех I/O, которые находятся в процессе в то время, когда случилась ситуация APD.
Как описано в KB 1015084, правильно отвязывать LUN с хоста ESX/ESXi 4.1 так (все делается на каждом из хостов):
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control) больше не используются для этого устройства.
Замаскировать LUN на хосте ESX/ESXi, следуя инструкциям KB 1009449 через модуль PSA (Pluggable Storage Architecture).
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESX/ESXi.
Удалить правила маскирования LUN, которые вы сделали на шаге 4 по инструкции в KB1015084.
Убедиться, что не осталось путей к устройству, после того, как вы проделали все эти операции.
Для ESX/ESXi 4.1 процесс достаточно сложный, теперь давайте посмотрим, как это выглядит в ESXi 5.
ESXi 5.0
В ESXi 5.0 появился новый статус Permanent Device Loss (PDL), то есть когда хост считает, что дисковое устройство уже никогда не будет снова подключено, а ситуация APD рассматривается как временный сбой, после которого хост снова увидит пути и устройство.
Чтобы избавиться от сложной процедуры отключения LUN от хостов ESXi, VMware сделала операции detach и unmount в интерфейсе vSphere Client и в командном интерфейсе CLI.
Вот тут можно найти unmount Datastore (но устройство продолжит быть доступным):
А вот тут находится detach для самого устройства:
Как описано в KB 2004605, чтобы у вас не возникло ситуации APD, нужно всего-лишь сделать detach устройства от хоста. Это размонтирует VMFS-том (если там есть какие-нибудь объекты - vSphere Client вам сообщит об этом).
Таким образом правильная последовательность отключения LUN в ESXi 5.0 теперь такова:
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control или Storage DRS) больше не используются для этого устройства.
Сделать detach устройства на хосте ESXi, что также автоматически повлечет за собой операцию unmount.
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESXi.
Ну и в качестве дополнительного материала можно почитать вот эти статьи:
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Компания VKernel (о которой мы много писали) выпустила очередную бесплатную, но весьма интересную утилиту - vScope Explorer. Объекты виртуальной инфраструктуры, включая хост-серверы, кластеры хранилища и виртуальные машины, с помощью утилиты можно визуализовать на dashboarde для виртуального датацентра, где видны основные источники проблем производительности, а также перегрузка ресурсов (вычислительных и хранилищ) и необходимые меры по добавлению новых мощностей:
Основные задачи, которые решает VKernel vScope Explorer:
Идентификация проблем с производительностью для виртуальных машин и хост-серверов в пределах не только одного датацентра, но и нескольких площадок под управлением нескольких серверов vCenter. В качестве движка продукта используется технология Capacity Analytics Engine.
Анализ текущего состояния вычислительных мощностей и информирование о том, как их необходимо увеличивать в случае их нехватки для виртуальных машин (Host Capacity Issues).
Анализ эффективности работы виртуальных машин и вывод информации о тех из них, которым выделено слишком много или, наоборот, слишком мало ресурсов.
Отчет об эффективности использования хранилищ: выводятся datastores, где место используется неэффективно (изолированные vmdk, выключенные машины, снапшоты, шаблоны и т.п.) - все это на одном экране для нескольких виртуальных датацентров.
Скачать бесплатный VKernel vScope Explorer можно по этой ссылке.
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
Мы уже писали о новом продукте VMware vSphere Storage Appliance (VSA), который позволяет создать кластер хранилищ на базе трех серверов (3 хоста ESXi 5 или 2 хоста ESXi 5 + физ. хост vCenter), а также о его некоторых особенностях. Сегодня мы рассмотрим, как работает кластер VMware VSA, и как он реагирует на пропадание сети на хосте (например, поломка адаптеров) для сети синхронизации VSA (то есть та, где идет зеркалирование виртуальных хранилищ).
Таги: VMware, VSA, vSphere, Обучение, ESXi, Storage, HA, Network
Режим SplitRx mode, который позволяет увеличить производительность сетевого взаимодействия для некоторых нагрузок
Функция VMX swap, которая уменьшает резервирование памяти для ВМ
Миграция vMotion по нескольким сетевым адаптерам (vmknics)
В документы присутствуют следующие темы:
Выбор оборудования для развертывания vSphere
Управление электропитанием
Настройка ESXi 5 для улучшения производительности
Настройка гостевой ОС для улучшения производительности
Настройка vCenter 5 и его базы данных для улучшения производительности
Производительность vMotion и Storage vMotion
Производительность Distributed Resource Scheduler (DRS) и Distributed Power Management (DPM)
Компоненты High Availability (HA), Fault Tolerance (FT) и VMware vCenter Update Manager
Документ обязателен к прочтению администраторам средних и крупных инфраструктур VMware vSphere 5. Кроме того, напомним о следующих новых документах о производительности платформы:
Вы уже читали, что в VMware vSphere 5 механизм отказоустойчивости виртуальных машин VMware High Availability претерпел значительные изменения. Точнее, он не просто изменился - его полностью переписали с нуля. То есть переделали совсем, изменив логику работы, принцип действия и убрав многие из существующих ограничений. Давайте взглянем поподробнее, как теперь работает новый VMware HA с агентами Fault Domain Manager...
Таги: VMware, vSphere, HA, Update, ESXi, Storage, vCenter, FDM
Вместе с релизом продуктовой линейки VMware vSphere 5, VMware SRM 5 и VMware vShield 5 компания VMware объявила о выходе еще одного продукта - VMware vSphere Storage Appliance. Основное назначение данного продукта - дать пользователям vSphere возможность создать общее хранилище для виртуальных машин, для которого будут доступны распределенные сервисы виртуализации: VMware HA, vMotion, DRS и другие.
Для некоторых малых и средних компаний виртуализация серверов подразумевает необходимость использовать общие хранилища, которые стоят дорого. VMware vSphere Storage Appliance предоставляет возможности общего хранилища, с помощью которых малые и средние компании могут воспользоваться средствами обеспечения высокой доступности и автоматизации vSphere. VSA помогает решить эти задачи без дополнительного сетевого оборудования для хранения данных.
Кстати, одна из основных идей продукта - это подвигнуть пользователей на переход с vSphere Essentials на vSphere Essentials Plus за счет создания дополнительных выгод с помощью VSA для распределенных служб HA и vMotion.
Давайте рассмотрим возможности и архитектуру VMware vSphere Storage Appliance:
Как мы видим, со стороны хостов VMware ESXi 5, VSA - это виртуальный модуль (Virtual Appliance) на базе SUSE Linux, который представляет собой служебную виртуальную машину, предоставляющую ресурсы хранения для других ВМ.
Чтобы создать кластер из этих виртуальных модулей нужно 2 или 3 хоста ESXi 5. Со стороны сервера VMware vCenter есть надстройка VSA Manager (отдельная вкладка в vSphere Client), с помощью которой и происходит управление хранилищами VSA.
Каждый виртуальный модуль VSA использует пространство на локальных дисках серверов ESXi, использует технологию репликации в целях отказоустойчивости (потому это и кластер хранилищ) и позволяет эти хранилища предоставлять виртуальным машинам в виде ресурсов NFS.
Как уже было сказано, VMware VSA можно развернуть в двух конфигурациях:
2 хоста ESXi - два виртуальных модуля на каждом хосте и служба VSA Cluster Service на сервере vCenter.
3 хоста ESXi - на каждом по виртуальному модулю (3-узловому кластеру служба на vCenter не нужна)
С точки зрения развертывания VMware VSA - очень прост, с защитой "от дурака" и не требует каких-либо специальных знаний в области SAN (но во время установки модуля на хосте ESXi не должно быть запущенных ВМ)...
Компания VMware в июле 2011 года объявила о доступности новых версий целой линейки своих продуктов для облачных вычислений, среди которых находится самая технологически зрелая на сегодняшний день платформа виртуализации VMware vSphere 5.0.
Мы уже рассказывали об основном наборе новых возможностей VMware vSphere 5.0 неофициально, но сейчас ограничения на распространение информации сняты, и мы можем вполне официально рассказать о том, что нового для пользователей дает vSphere 5.
Как вы уже знаете, VMware vSphere 5 будет уже только на базе гипервизора ESXi, а выпуск продукта ESX прекращается (версия 4.1 - последняя на базе этой платформы). Поэтому тем, кто еще не перешел на VMware ESXi нужно задумываться о миграции.
Мы уже писали на тему того, как перейти с ESX на ESXi (тут, тут и тут), а сегодня расскажем в общих чертах о плане миграции таких хост-серверов и о том, что делать после установки нового ESXi (пост-миграционные процедуры).
Это, по-сути, средство сбора отчетности о виртуальной инфраструктуре VMware vSphere и виртуальных машинах, что-то вроде бесплатного Veeam Reporter Free.
В категории Performance мы можем увидеть следующую информацию:
Host/VM Utilization Heat Map - в этой категории представлены хосты и виртуальные машины с наибольшей загрузкой вычислительных ресурсов. Весьма полезно для развертывания новых ВМ.
Host Top CPU Ready Queue - параметры метрики производительности CPU Ready. Подробнее об этом счетчике тут.
Storage Access IOPS - здесь мы видим нагрузку на виртуальные хранилища по IOPs (на и из Datastore).
В категории Efficiency мы можем увидеть следующую информацию:
VM Over/Under Provisioning - показывает недогруз или перегруз по ресурсам для виртуальных машин на хост-серверах.
Storage Wasted Allocations - ранжированно показывает, где у нас на хранилище лежит непойми что (не относящееся к ВМ) и их недозаполненность.
Storage Allocated to Dormant VMs - показывает какие ВМ не используются и сколько выделено под них хранилища.
VM Rightsizing Recommendations - показывает рекомендации по сайзингу ВМ с точки зрения производительности (типа добавить или удалить vCPU).
Но этот продукт для небольшой инфраструктуры, а нормальные пацаны с табуном серверов ESX / ESXi скачивают и покупают продукт Veeam Reporter, который позволяет вести трекинг изменений виртуальной инфраструктуры VMware vSphere и получать отчетность обо всех ее аспектах. Тем более, что недавно вышел бесплатный аддон к нему - Capacity Planning Report pack for Veeam Reporter.
Скачать же бесплатный VMTurbo Performance and Efficiency Reporter можно по этой ссылке.
Как вы знаете, VMware vSphere 5 будет построена только на базе гипервизора VMware ESXi (а ESX больше не будет) и выйдет уже в этом году, поэтому мы публикуем серию заметок о том, как перейти на ESXi с ESX (вот тут - раз и два).
Сегодня мы поговорим о таком различии, как Scratch Partition в ESXi. Scratch Partition - это специальный раздел на хранилище для хост-сервера, который не обязательно, но рекомендуется создавать. Он хранит в себе различную временную информацию для ESXi, как то: логи Syslog'а, вывод команды vm-support (для отправки данных в службу поддержки VMware) и userworld swapfile (когда он включен). Он создается, начиная с vSphere 4.1 Update 1 автоматически, и, если есть возможность, на локальном диске.
Так как данный раздел является необязательным, то в случае его отсутствия вся перечисленная информация хранится на ramdisk хост-сервера (который, кстати, отъедает память - 512 MB). И, так как это ramsidk, после перезагрузки эта информация (если у вас нет scratch partition) очищается. Поэтому неплохо бы этот раздел, все-таки, создать.
По умолчанию, этот раздел создается в системе vfat и составляет 4 ГБ. Это много. Почему так много? Объяснение такое, что местечко оставлено под будущие версии ESXi. Этот раздел может размещаться локально или на SAN-хранилище. При этом его могут использовать несколько хостов ESXi одновременно, поэтому рекомендуется сделать его гигов 20. Но для каждого должна быть своя locker-директория на этом разделе.
Через vSphere Client scratch partition настраивается так:
Соединяемся с хостом ESXi из vSphere Client.
Переходим на вкладку Configuration.
Переходим в категорию Storage.
Нажимаем правой кнопкой на datastore и выбираем Browse.
Создаем уникальную директорию для хоста ESXi (например, .locker-ESXiHostname)
Закрываем Datastore Browser.
Переходим в категорию Software.
Нажимаем Advanced Settings.
Переходим в раздел ScratchConfig.
Устанавливаем в качестве значения ScratchConfig.ConfiguredScratchLocation директорию, которую только что создали, например:
/vmfs/volumes/DatastoreName/.locker-ESXiHostname
Нажимаем OK.
Перезагружаем ESXi.
Все это можно настроить и при автоматизированном развертывании VMware ESXi через kickstart. А можно и через vCLI и PowerCLI. О том, как это сделать, читайте в KB 1033696.
О решении StarWind Enterprise iSCSI для создания отказоустойчивых хранилищ VMware vSphere и Microsoft Hyper-V мы уже писали немало (для этого есть специальный раздел на нашем сайте) и будем писать еще, пока все кому оно нужно его не купят. А нужно оно очень многим, так как позволяет создать отказоустойчивый кластер хранения на базе существующей инфраструктуры Ethernet при минимальных инвестициях (не надо покупать FC-хранилища, устройства коммутации SAN и прочее).
Сегодня мы поговорим о типе диска Snapshot and CDP Device в StarWind Enterprise iSCSI. Во-первых, вам нужно прочитать первую часть статьи, где описаны основные режимы работы дисков со снапшотами, которые поддерживает продукт.
Диски типа Snapshot and CDP Device можно создать, когда вы выбираете опцию создания виртуального образа Advanced Virtual, а затем Snapshot and CDP Device:
CDP - это Continuous Data Protection, т.е. непрерывная защита данных ваших виртуальных машин. В этом режиме поддерживаются мгновенные снимки хранилища (snapshots), которые защитят вас от утраты каких-либо важных данных по вине пользователя - вы всегда сможете откатиться к снимку, созданному в определенный момент времени.
Какие опции мы имеем (кстати, обратите внимание, что StarWind можно использовать и для Citrix XenServer, где он находится в официальном HCL):
Во-первых, у нас есть три режима работы диска Snapshot and CDP Device...(нажимаем читать дальше и комментировать)
Вы, наверняка, слышали про компанию VKernel, которая производит средства для управления виртуальной инфраструктурой VMware vSphere. Исторически сложилось так, что продукты компании часто перекрываются их аналогами со стороны VMware (например). Вот и не так давно вышел в свет продукт VKernel Performance Analyzer 1.0, являющийся частью пакета vOperation Suite. Он является прямым конкурентом VMware vCenter Operations, о котором мы писали на прошлой неделе.
Предназначен VKernel Performance Analyzer для обнаружения проблем в виртуальной инфраструктуре vSphere в реальном времени на базе алармов VMware vCenter. Приводится детальное описание проблемы производительности объекта (например, виртуальной машины), а дальше предлагается, что с этой виртуальной машиной можно сделать (а в колонке Action предлагается действие, которое можно сделать прямо из интерфейса программы):
Зацените, кстати, имена машин русские - это все потому, что чуваки сидят под Москвой.
Небольшой обзор о функционале VKernel Performance Analyzer 1.0:
Требования к VKernel Performance Analyzer такие:
VMware ESX 3.0 и vCenter 2.5 и выше
1 vCPU если у вас меньше 200 ВМ, 2 vCPUs если у вас 200-1500 ВМ, 4 vCPUs - более 1500 ВМ
3 ГБ памяти
10 ГБ дискового пространства
Что умеет VKernel Performance Analyzer:
Мониторинг тревог vCenter с рекомендациями по разрешению проблем
Поиск виртуальных машин и других объектов (например, Datastore), испытывающих проблемы с производительностью
Решение проблем в один клик за счет действий, выполняемых при интеграции с vCenter
Карта узких мест виртуальной инфраструктуры (недостаток ресурсов)
Отчет о проблемах производительности инфраструктуры с указанием путей их устранения
Alarm by Virtual Object Heat Map - проблемы производительности выраженные через алармы vCenter для всех объектов vSphere
Нотификации по трендам загрузки
Графики использования ресурсов для объектов
vCenter Alert Auto-configurator - установка алармов vCenter в соответствии с лучшими практиками
Обзорное видео по продукту:
Скачать VKernel Performance Analyzer можно по этой ссылке.
P.S. Кстати, Милош, хватит там отсиживаться - давайте уже покупайте рекламу на VM Guru. О вас тут мало кто знает, а реклама - это двигатель сам знаешь чего. Для кого тут баннер справа висит:)
Как вы знаете, у компании VMware есть проприетарная система VMFS (официально называемая "VMware Virtual Machine File System"), которая представляет собой распределенную кластерную файловую систему с возможностью одновременного доступа со стороны нескольких хост-серверов VMware ESX / ESXi. VMFS имеет версии, которые можно увидеть в свойствах Datastore в vSphere Client:
VMFS версии 3 впервые появилась в VMware ESX 3.0 (тогда же она перешла от плоской структуры к структуре директорий). Теперь же версии VMFS соответствуют следующим версиям хостов их создавшим:
ESX 3.0 - VMFS 3.21
ESX 3.5 - VMFS 3.31 (новая возможность: optimistic locking - сбор локов в пачки, что повышает производительность при SCSI-резервациях)
ESX 4.0 - VMFS 3.33 (новая возможность: optimistic IO - увеличение эффективности канала ввода-вывода при работе с метаданными тома)
Казалось бы нужно обновлять виртуальные хранилища, чтобы они поддерживали все новые возможности новых версий VMware vSphere. А хранилище VMFS никак обновить нельзя - его можно только создать заново более новой версией, предварительно освободив. Но ничего этого делать не нужно.
Все нововведения по работе с хранилищами делаются со стороны драйвера VMFS на хост-сервере VMware ESX / ESXi, а на самом томе VMFS только ставится маркер версии драйвера его отформатировавшего (например, в datamover'е). Хотя, говорят, в самой структуре тома говорят тоже происходят незначительные изменения. Но все это значит, что на Datastore, созданном из ESX 3.0 (VMFS 3.21), вы можете использовать все функции ESX 4.1 (VMFS 3.46) по работе с хранилищами, например, Thin Provisioning или VMFS Volume Grow (хотя вот про последнее есть иные мнения).
Компания VMware на прошлой неделе выпустила продукт VMware vCenter Operations, который позволит системным администраторам и менеджерам датацентров обнаруживать, анализировать и решать проблемы производительности VMware vSphere.
vCenter Operations собирает данные о производительности каждого из объектов виртуальной инфраструктуры VMware vSphere (виртуальные машины, хранилища, кластеры, датацентр в целом), хранит их в централизованной базе данных, анализирует их и делает отчет в реальном времени о текущих проблемах производительности, а также о потенциальных проблемах.
Есть разные представления данных:
Основные особенности vCenter Operations:
Комбинирование ключевых метрик производительности в общее количество баллов для датацентра (CPU, memory, disk, contention performance).
vCenter Operations вычисляет диапазон значений, который находится в рамках допустимой производительности, и подсвечивает отклонения от этого диапазона.
Графическое представление инфраструктуры в контексте производительности с возможностью "проваливания" до отдельных компонентов.
Отображение информации об изменениях в иерархии виртуальной инфраструктуры, после чего vCenter Operations показывает, как эти изменения отразились на производительности различных объектов. Например, если виртуальная машина переместилась за счет vMotion между хостами VMware ESX, vCenter Operations покажет нам как изменилась нагрузка на хост-серверы.
Обзорное видео:
В продукте три основных аспекта представления информации о производительности виртуальной инфраструктуры vSphere:
health - текущее состояние объекта или всего виртуального датацентра. Им назначаются очки, исходя из допустимых значений нормальной производительности, а также на основе исторических данных. Если показатели метрик выходят за данные значения - vCenter Operations оповещает об этом и сообщает о возможных причинах.
analytics - на основе загрузки текущих метрик с помощью данного представления можно определить, какие объекты простаивают (например, хост-серверы), а какие требуют выделения дополнительных ресурсов (например, виртуальная машина).
capacity - показывает какой процент емкости от физических ресурсов занимает тот или иной объект. Далее за счет модуля аналитики можно узнать время, когда ресурсов окажется недостаточно (например, заполнится Datastore) и сделать долгосрочные прогнозы по добавлению новых мощностей в инфраструктуру (вычислительные ресурсы, хранилища).
vCenter Operations поставляется в 3-х изданиях: Standard, Advanced и Enterprise:
Standard
Advanced
Enterprise
Performance Management
Alerting and Visualization
Consolidated Health dashboard
Actionable health scores & KPIs
Top N priority views
Self learning behavior
Dynamic Thresholds
Early warning visualizations
Predictive 'Smart' Alerts
Alert lifecycle mgmt
Custom alerts
Email & SNMP notifications
Analysis & Troubleshooting
1 click root-cause dashboard w/ KPI history
Impact detection (Health trees)
Behavioral performance/workload analysis
Multiple KPI anomaly correlation
Contextual event overlays
HeatMap library
Cross Team views & enablement
Role based access & SSO
Actionable operator views
Problem isolation tools
Report by Custom Groups
vSphere awareness
Multi vCenter support
Integrated into vSphere Client
vSphere Inventory & dependency aware
Support for Reservations & Limits
Capacity Management
Capacity Awareness
Past, present, future capacity summaries
Current capacity bottlenecks
Future capacity shortfall notifications
Alerts on capacity conditions
Schedulable Capacity Reports
Report across multiple vCenters
Capacity Optimization
Analyze & trend resource wastage
Identify over-allocated, idle VMs
Identify under-utilized hosts, clusters
Identify waste from snapshots, templates, orphaned
VMs
Recommendations to reclaim resources
Recommendations to rightsize
Capacity Planning & Forecasting
Estimate remaining capacity
Estimate time remaining to full capacity
Forecast demand & supply
Trend Utilization vs demand
Trend Utilization and allocation
Replenishment recommendations
Interactive What-if modeling
Support for vSphere storage
Support for Peak usage
Support for Business time zones
Cross Team views & enablement
Role based access & SSO
Actionable operator views
Report by Custom Groups
Infra. utilization trend views for Upper mgmt
Supply forecast for provider teams: Storage, Network, Build
Usage & Optimization views for LOB
Cloud capacity reports for Provider & Tenants
Report customization
vSphere awareness
Integrated into vSphere Client
vSphere Inventory & dependency aware
Support for vCloud objects(vDCs)
Support for Thin Provisioning
Support for Reservations & Limits
Support for Linked Clones
Support for HA, FT
Configuration & Compliance Management
Configuration Visibility
Configuration and change visibility
Centralized dashboards
Out of box Reports
Change alerts
Continuous Compliance
Guest Compliance
Host Compliance
vCenter Compliance
Standard Regulatory compliance (SOX, HIPAA, DISA, ISO, BASEL II, PCI DSS, NIST)
Custom policy compliance
Automated compliance violation detection
Compliance remediation recommendations
Compliance remediation automation
Automated Provisioning and Patching
Manage OS distribution centrally
Discover new systems, build/deploy via PXE
Provision ESX/ESXi to "bare metal"
Provision OS to bare metal & VMs
Build and deploy software packages (Windows)
Connect to compliance policies
Automatically detect missing software
Remediate non-compliant systems
Distributed software repository
Cross Team Views & enablement
Role based access control
Active Directory integration
Скачать vCenter Operations с сайта VMware нельзя. Для запроса детальной информации обращайтесь к партнерам компании VMware.
Компания Veeam Software на днях объявила о выпуске второй версии бесплатного продукта Veeam Business View 2.0. Мы уже писали об этом продукте - он представляет собой плагин для нескольких продуктов Veeam (например Veeam Backup and Replication и Veeam Monitor), с помощью которого можно разбить объекты виртуальной инфраструктуры не так, как нам показывает VMware, а своим собственным образом (например, на основе бизнес-единиц предприятия). Но при этом, это отдельный бесплатный продукт, развертываемый и настраиваемый отдельно.
Veeam Business View 2.0 расширяет возможности организации объектов виртуальной инфраструктуры. Теперь можно создавать представления хостов VMware ESX, кластеров HA/DRS и хранилищ (datastores). При этом создаваемые группы являются динамическими.
Например, вы определяете выражение для категоризации виртуальных машин по числу виртуальных процессоров - 1 vCPU, 2 vCPU, 4 vCPU. Затем Veeam Business View создает группы в соответствии с определенными правилами именования объектов и помещает туда представление виртуальных машин по группам для разных продуктов (например, Veeam Monitor или Reporter).
Еще пример - вы определяете граничные значения заполненности для своих хранилищ: если оно заполнено меньше чем на 70% - делаете группу ""Underutilized", если на 70-90% - группу "Normal", а если больше 90% - "Overutilized". И далее при построении отчетов в Veeam Reporter или мониторинге с помощью Veeam Monitor вы будете оперативно видеть определенные вами группы хранилищ по категориям. При этом все эти категории будут обновляться автоматически при добавлении, удалении или изменении объектов виртуальной инфраструктуры. То есть работает это в стиле "Set and Forget".
Кроме того, в Veeam Business View 2.0 появился расширенный Dashboard, на котором видно, сколько объектов виртуальной инфарструктуры VMware vSphere уже категоризованы. То есть это обзор вашей инфраструктуры с высоты "птичьего полета".
Ну и по-сути, что еще появилось в Veeam Business View 2.0:
Новые правила определения категорий: не только по географическому принципу или по именам объектов, но и по их свойствам - например, процессоры хост-серверов в мегагерцах.
Исключения для объектов при категоризации (например, вы не хотите чтобы тестовые машины появлялись в представлениях).
Интеграция со сторонними приложениями, например, со службой каталога Microsoft Active Directory, куда можно отобразить изменения, сделанные в Veeam Business View 2.0.
Скачать аддон Veeam Business View 2.0 для своих продуктов Veeam можно по этой ссылке. Документация вот тут.
Таги: Veeam, Business View, Update, vSphere, ESX, Monitor, Reporter, Backup
Копировать руками машину каждый раз, когда нужно внедрить какое-то оборудование, или просто для сохранения данных, это безумно неудобно. Вот для этого и была придумана технология автоматизированного бэкапа, написанная энтузиастами на скриптах perl: ghettoVCB.

 RSS
RSS